TAC12 TV – Tarragona's economy resists international conflicts
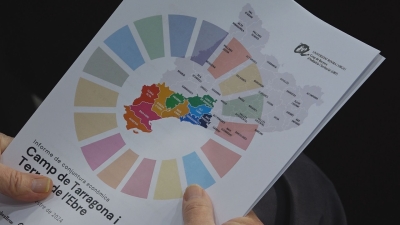
The economy of Camp de Tarragona remains stable despite international conflicts that could change the macroeconomic scenario. This is evidenced…
All Latest News For You!
The economy of Camp de Tarragona remains stable despite international conflicts that could change the macroeconomic scenario. This is evidenced…
Assunta case It is the most talked about series on Netflix in recent weeks. A production that premieres today on…
Unfortunately, I find more and more cases when consulting people with gastrointestinal symptoms but without a clear diagnosis. At this…
Here is the expected lineup for the Bologna-Udinese match: ▪ Bologna – Udinese – Sunday, 3pm, Stadio Dallara▪ Referee Saki▪…
What is for'icon With the Double arrow View on WhatsAppbut who can everyone still see? Soon this symbol will be…
Thales is gaya The living legend of the so-called new journalismAt 92, he is prolific as a writer, and although…
Francis Murray He once again reviewed the weather that awaits us this weekend. Although many people take advantage of the…
“The world’s grape and wine sector facesDifficult challengesThis is partly due to the effects of climate change and pressures Inflationists…
El Balloon Museum d'Emily in Paris in the Barcelona areaEPC Fans of Emily in Paris, the popular Netflix series, will…
Sometimes, we can feel our defenses being diminished, manifested by excessive fatigue, frequent illnesses, or slow recovery from colds. If…








