The county council is calling for urgent improvements to the district's Renfe neighborhood service.
the Anger among passengers at Pécs Penedès It never stops growing at the same rate it grows Accidents on the…
All Latest News For You!
the Anger among passengers at Pécs Penedès It never stops growing at the same rate it grows Accidents on the…
BarcelonaUsing ceramics, Miquel Barcelo (Filantics, 1957) travels through time. In the documentary Barcelo, traces of fangsWhich was shown for the…
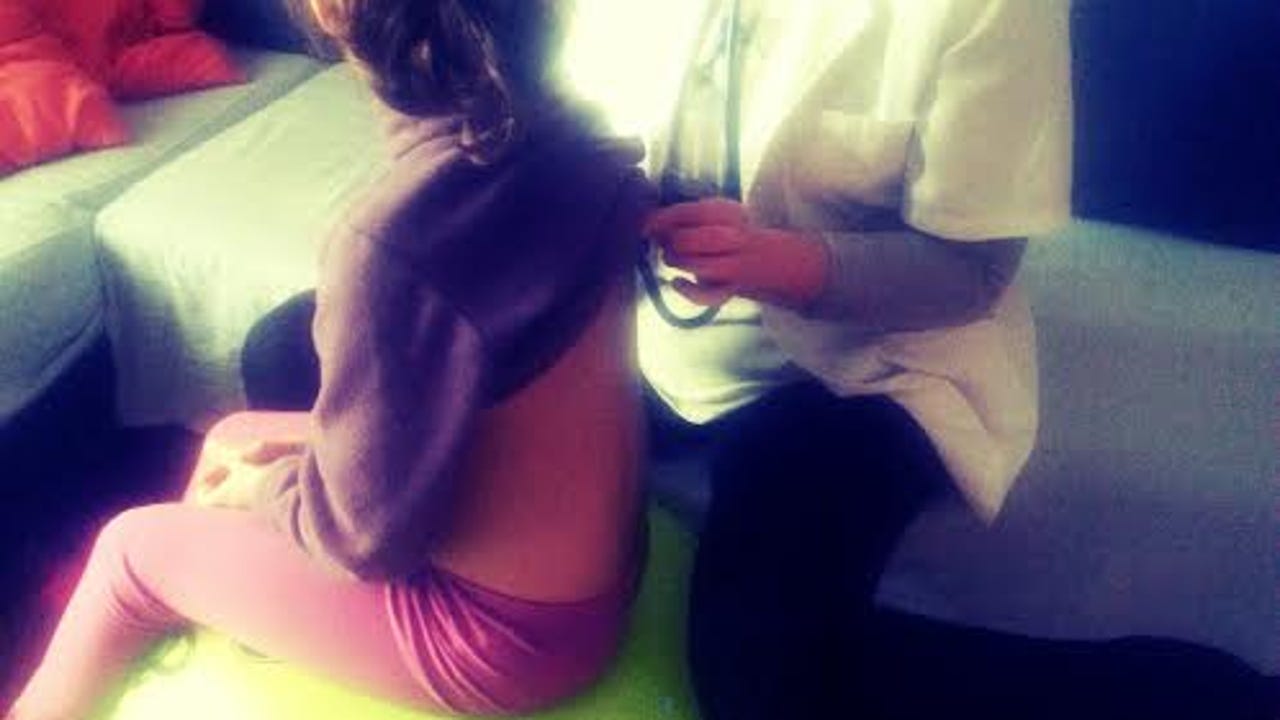
the Cystic fibrosis It is a hereditary disease Genetically This affects some Twenty children Of the total number of people…
The Italian, Fiorentina coach, is brief: “Milenkovic’s expulsion, which was not very clear, was decisive. With ten of us, it…
More dynamism – It will arrive at dealers inSummer 2025Its price is supposed to start at about 40 thousand euros,…
Carles Planas Thor journalist specialized in Technology and its social and political impact. Located Barcelona Version + Barcelona – Thursday,…
(ACN) A motorcyclist died This Wednesday in one Traffic accident on the coastal roundaboutOn his way through San Adria de…
redis He has completed the adaptation work for what will be his Central quadrant Companies, REDESA Building innovation. This procedure,…
The Cultural Week of the Municipal Music School of La Seu d'Urgell presents the conference and presentation.History of Music: The…
La hidratació exercix un paper central en el procés d’aprimar. És el teu objectiu? En la cerca constant de mètodes…